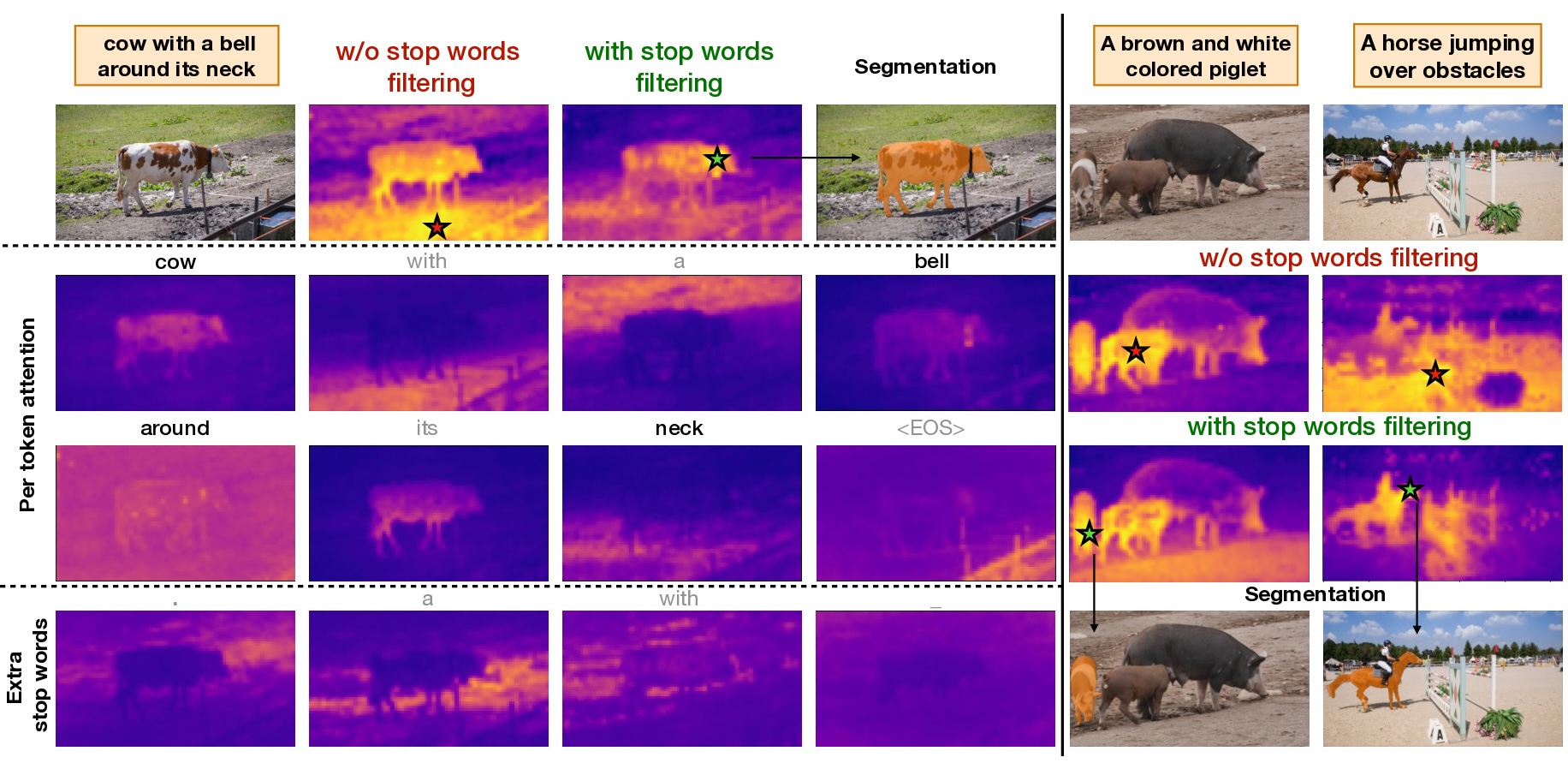
Method Overview
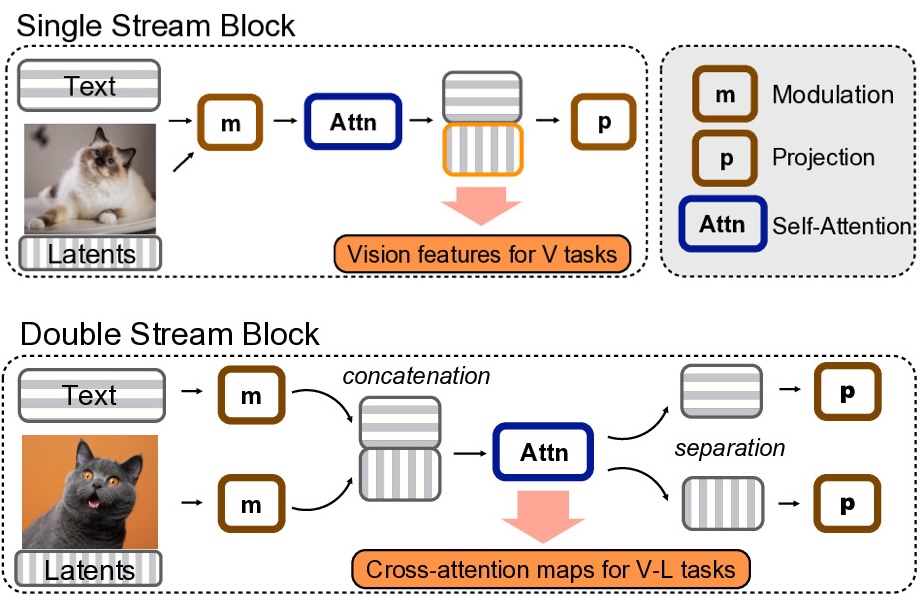
Extracting DiT Features. We introduce RIFF and iRIFF, methods for extracting semantic features from rectified flow models using DiT architectures. RIFF injects scaled noise into clean latents, while iRIFF leverages flow inversion to obtain structured latents aligned with the data distribution. Features are extracted from intermediate DiT attention blocks, outperforming traditional U-Net-based features. The diagram shows double- and single-stream transformer blocks, highlighting semantic feature extraction points. V-L denotes vision-language tasks and V denotes vision tasks.